Raid 1 degraded что делать?
Raid 1 degraded что делать?



| Текущее время: Чт авг 12, 2021 23:48 |
Часовой пояс: UTC + 3 часа
Raid 1 is degraded (Разрушился RAID1, DNS-325)
После проверки целостности диска (Scan Disk) получил:
«Warning : The device with Raid 1 is degraded now. Please remember to rebuild the Raid 1 for data integrity.
Auto-Rebuild Configuration allows you to enable or disable the Auto-Rebuild feature. You can also manually rebuild by clicking the Manually Rebuild Now button. Please note that rebuilding will erase all data on the newly inserted drive.»
Все диски пустые, я в шоке, все за больше чем 1 год пропало. Как, как такое может быть? Зачем тогда рейд 1? Ребята из DLink, что вы выпускаете?
Начал разбираться. Купил адаптер USB-SATA. Установил R-Linux, вытащил диски из NAS, начал последовательно подключать через адаптер.
Левый диск — файловая система: Ext4: — диск пустой
Правый диск — файловая система: Ext4 — увидел знакомое дерево директорий, попробовал открыть несколько фотографий, к моему счастью файлы открылись, появилась надежда что можно возможно все восстановить.
Решил сделать побитовую копию правого диска на другом диске (пришлось еще купить диск на 2 Тб), чтобы не проводить эксперименты на оригинальном диске из NAS, провел клонирование диска с помощью Acronics True Image через загрузочный образ, которое завершилось не успешно после 18 часов работы.
Решил повторить попытку уже из-под Windows, процесс начался заметно быстрее, вечером возможно буду изучать результаты.
А как Вы изначально определили, что все диски пустые? Если даже RAID развалился и не отображается в системе — данные никак самостоятельно стереться с дисков не могут. Раздел Volume_1 отображался в системе? Если статус был degraded, то можно было запустить процесс восстановления средствами накопителя.
А как Вы изначально определили, что все диски пустые? Если даже RAID развалился и не отображается в системе — данные никак самостоятельно стереться с дисков не могут. Раздел Volume_1 отображался в системе? Если статус был degraded, то можно было запустить процесс восстановления средствами накопителя.
Доброе время суток! Да, NAS мне предлагал восстановить диски, но Вы думаете я доверюсь системе, которая при «безопасной» операции проверки дисков на ошибки разрушила зеркало?
И таки да, при игнорировании операции восстановления, данных на зеркале не было и можно было создать директорию через встроенный файловый менеджер веб-интерфейса, что конечно я не сделал.
После попытки сделать клон диска из-под Windows, через Acronis True Image 2014, после 18 часов работы, попытка не увенчалась успехом. Через некоторое время поисков в Интернет, я нашел драйвер ext4 для Windows Ext2Fsd и решился его использовать на свой страх и риск. Установил, подключил правый диск разрушенного зеркала и. я увидел нужную мне структуру директорий, получил доступ к файлам, которые я уже думал потерял навсегда.
В настоящий день уже больше 12 часов идет копирование файлов и архивов и проверка их целостности. Пока боюсь загадывать, но приблизительно 98-99% информации думаю получится восстановить. Но часть файлов около 1-2% все равно стали недоступными, хотя они присутствуют в каталоге, думаю вернуться к ним после завершения восстановления основных файлов.
Интересные выводы. Диски, работающие в зеркале в NAS-325 (SMART обоих дисков показывает отличное их здоровье), благодаря безобидной операции логически разрушились, на одном диске информация потерялась полностью, на другом на 1-2%, мне повезло. могло бы быть гораздо хуже. Доверие к программным рейдам в лице NAS-325 и к компании DLINK подорвано навсегда.
Восстановить всю возможную информацию через ext2fsd, не получилось, порядка 8-9% информации не удалось извлечь. Ряд файлов присутствуют в каталогах, но скопировать их не получилось, возникает ошибка копирования. Наличие их в каталоге подвигло меня дальше искать варианты их восстановления. С помощью утилиты WinMerge я составил для себя список файлов, которые не получилось скопировать. Потом я вернулся опять к утилите R-Linux, предварительно удалив драйвер ext2fsd из системы.
После сканирования диска в течении 4-5 часов, я увидел ту же иерархию каталогов, что и через ext2fsd, руководствуясь списком не скопированных файлов, я попытался восстановить их и. у меня получилось! Файлы скопировались и похоже, что удастся существенно снизить процент потерь информации. продолжение следует.
Вот и закончилась эпопея с восстановлением казалось бы потерянной информации. длинною в 1 неделю. Компьютер копировал, восстанавливал и гонял терабайты информации между дисками круглосуточно. Удалось восстановить всю важную информацию и частично менее важную. Потери составили порядка 1% от объема исходной информации.
DNS-325 — это не надежное хранилище ваших файлов, если за время его эксплуатации (порядка 1,5 года) железо не подводило, то софт конечно глючил. RAID1 в нем — это фикция, последний глюк окончательно подтвердил это, никакого доверия. Храните данные на нем, которые не жалко потерять. Начал искать более надежное хранилище.
Не понятно вообще никому. «корневой» папкой я в данном случае назвал одну из папок в расшаренной Volume_1.
А как понять «открыть доступ» и «посмотреть, что внутри»? И есть ли смысл в это фразе, если объём занимаемой информации уменьшился на порядка 600 Гб? И если оба диска при монтировании видятся с ext4 одинаковыми? и если testdisk видит удалённые папки и файлы? только пишет что они «damaget»?
Но всё это ещё даёт шансы на восстановление — кроплю, пробую варианты полного сканирования, создал образ и работаю уже с ним — завтра буду пробовать стандартные средства для работы с ext4.
В голове до сих пор один вопрос: КАК, Б**ДЬ.
Как удалилась полностью одна папка из Volume_1 и как из другой папки удалились половина подпапок и половина файлов.
Пока все попытки натыкаются на «ошибки файловой системы».
настроение ни к чёрту.
Часовой пояс: UTC + 3 часа
Кто сейчас на форуме
Сейчас этот форум просматривают: нет зарегистрированных пользователей и гости: 1
Вышел из строя диск RAID 5. Можно ли путем замены диска восстановить корректную работу RAID?
Позвольте, я процитирую:
>>
Когда происходит выход из строя (полный или частичный) одного из дисков группы типа RAID-5, то RAID-группа переходит в состояние degraded, но наши данные остаются доступными, так как недостающая часть их может быть восстановлена за счет избыточной информации того самого «дополнительного объема, размером в один диск». Правда обычно быстродействие дисковой группы резко падает, так как при чтении и записи выполняются дополнительные операции вычислений избыточности и восстановления целостности данных. Если мы вставим вместо вышедшего из строя новый диск, то умный RAID-контроллер начнет процедуру rebuild, «перестроения», для чего начнет считывать со всех дисков оставшиеся данные, и, на основании избыточной информации, заполнит новый, ранее пустой диск недостающей, пропавшей вместе со сдохшим диском частью.
Если вы еще не сталкивались с процессом ребилда RAID-5, вы, возможно, будете неприятно поражены тем, насколько длительным этот процесс может быть. Длительность эта зависит от многих факторов, и, кроме количества дисков в RAID-группе, и их заполненностью, что очевидно, в значительной степени зависит от мощности процессора RAID-контроллера и производительности диска на чтение/запись. А также от рабочей нагрузки на дисковый массив во время проведения ребилда, и от приоритета процесса ребилда по сравнению с приоритетом рабочей нагрузки.
Если вам не посчастливилось потерять диск в разгар рабочего дня или рабочей недели, то процесс ребилда, и так небыстрый, может удлинниться в десятки раз.
А с выходом все более и более емких дисков, уровни быстродействия которых, как мы помним, почти не растут, в сравнении с емкостью, время ребилда растет угрожающими темпами, ведь, как уже писалось выше, скорость считывания с дисков, от которой напрямую зависит скорость прохождения ребилда, растет гораздо медленнее, чем емкость дисков и объем, который нужно считать.
Так, в интернете легко можно найти истории, когда сравнительно небольшой 4-6 дисковый RAID-5 из 500GB дисков восстанавливал данные на новый диск в течении суток, и более.
С использованием же терабайтных и двухтерабайтных дисков приведенные цифры можно смело умножать в 2-4 раза!
И вот тут начинаются страсти.
Дело в том, и это надо себе трезво уяснить, что на время ребилда RAID-5 вы остаетесь не просто с RAID лишенным отказоустойчивости. Вы получаете на все время ребилда RAID-0
RAID-5 в состоянии «degraded» эквивалентна отсутствию RAID вообще.
Поэтому лучшей стратегий будет забрать оттуда остатки информации, т.е. сделать бэкап.
Это будет медленно, но это ещё возможно.
Ребилд массива повысит вероятность выхода из строя оставшихся дисков и тогда вы не сможете сделать бэкап даже медленно.
Продолжим цитирование
>>
Так, например, для 6-дискового RAID-5 с дисками 1TB величина отказа по причине BER оценивается в 4-5%, а для 4TB дисков она же будет достигать уже 16-20%.
Эта холодная цифра означает, что с 16-20-процентной вероятностью вы получите отказ диска во время ребилда (и, следовательно, потеряете все данные на RAID). Ведь для ребилда, как правило, RAID-контроллеру придется прочитать все диски, входящие в RAID-группу, для 6 дисков по 1TB объем прочитанного RAID-контроллером потока данных с дисков достигает 6TB, для 4TB он уже станет равным 24TB.
24TB это, при BER 10^15, четверть от 110TB.
Но даже и это еще не все.
Как показывает практика, примерно 70-80% данных, хранимых на дисках, это так называемые cold data. Это файлы, доступ к которым сравнительно редок. С увеличением емкости дисков их объем в абсолютном исчислении также растет. Огромный объем данных лежит, зачастую, нетронутый никем, даже антивирусом (зачем ему проверять гигабайтные рипы и mp3?), месяцами, а возможно и годами.
Ошибка данных, пришедшаяся на массив cold data обнаружится только лишь в процессе полного чтения содержимого диска, на процесс ребилда.
>>
Итак, ребилд массива с вероятностью 20% приведёт к ошибке и развалу всего RAID.
Из-за чтения дурацких «cold data» вы с вероятностью 20% потеряете ценнейшие «hot data».
Чем раньше будет выявлена ошибка или нестабильность в данных, тем лучше. Конечно, лучше при бэкапе, чем при ребилде.
С другой стороны, если бэкап грамотный, он холодные данные не будет читать, только изменившиеся.
Поэтому для особо важных данных еще отдельно scrubbing делают.
А вообще, BER — это чисто маркетологический параметр. Делают одинаковые диски, в них заливают немного разные прошивки — и вуаля: у одного диска BER 10e14, а у другого — 10e16. В реальности вероятность ошибки гораздо ниже, при этом совсем не факт что она вообще будет обнаружена. НЯП, изначально эта цифра рассчитывалась как вероятность ошибке при «безошибочном» чтении. Т.е. вероятность того, что ошибка будет пропущена, и считанные данные будут неверными. Т.е. это вероятность искажения данных, а не read error.
Вероятность отказа дисков при ребилде вычисляется исходя из MTBF. Т.е., например, если 6-дисковый массив ребилдится сутки — наработка составит 6*24 часа, что, например, при 1,2 млн. часов MTBF дает вероятность 0,012%. Если бы это было не так — в датацентрах требовалась бы куча админов для жонглирования дисками.
Восстанавливаем RAID 5, 1 или 0 при поломке одного или нескольких дисков
В нашем пошаговом руководстве, я расскажу о нескольких методах восстановления информации с программных RAID 5, 0 или 1, которые собраны под «Linux».

Если один или несколько физических накопителей повреждены, то кажется что восстановить данные просто невозможно. На самом деле это не так, объем информации, который можно достать из массива, сильно зависит от типа RAID и количества сломанных носителей.
Программный RAID крайне ненадежная штука, отключите всего один накопитель и весь массив перестанет определяться системой. Массив с поломанным носителем, можно пересобрать при помощи специальных программ, в наших тестах я буду использовать Hetman RAID Recovery. После запуска, она автоматически определит тип контроллера, название программы или производителя материнской платы, на основе технологий которых был собран RAID. Потом утилита соберет его из оставшихся «живых» накопителей, просканирует и найдет всю оставшуюся информацию, которую можно будет сохранить в другое место.
Установочный файл программы есть только под ОС Windows. Чтобы запустить ее под Linux понадобиться, либо установить дополнительную систему на компьютер, либо воспользоваться виртуальной машиной под Windows. В нашем случае, я выбрал второй вариант.
Восстанавливаем файлы с RAID-1
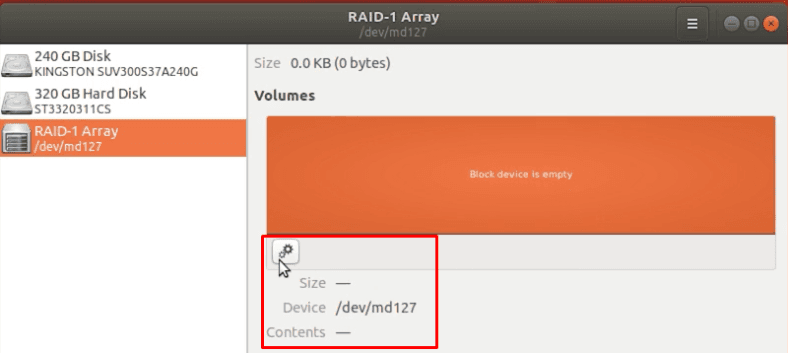
Тестовый массив первого типа состоит из двух одинаковых накопителей. Этот тип очень надежен сам по себе, так как может состоять из четного количества физических дисков, которые работают как «полное зеркало». Если поврежден только один носитель, то все устройство невозможно смонтировать в Linux.
Запускаем программу, она нашла и пересобрала устройство, все параметры указаны верно.
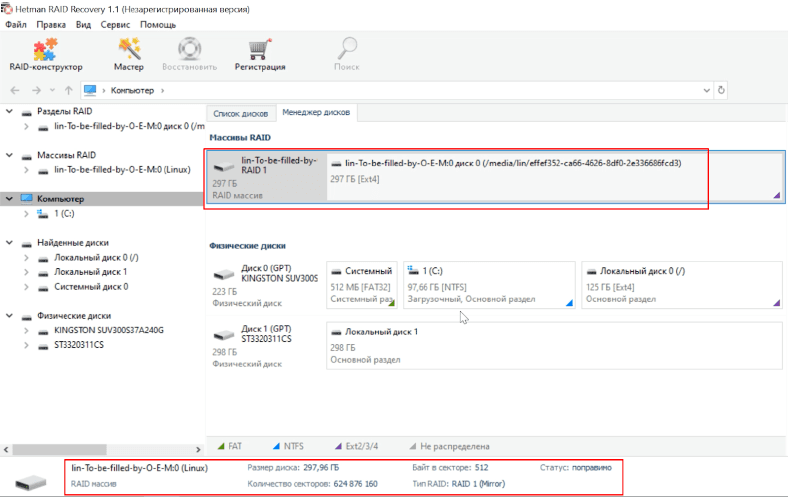
Так как, «живой» диск содержит полноценную копию всей информации, то запускаем быстрый анализ, отмечаем нужные нам файлы и каталоги, сохраняем на любой другой диск.

Восстанавливаем данные с RAID 5
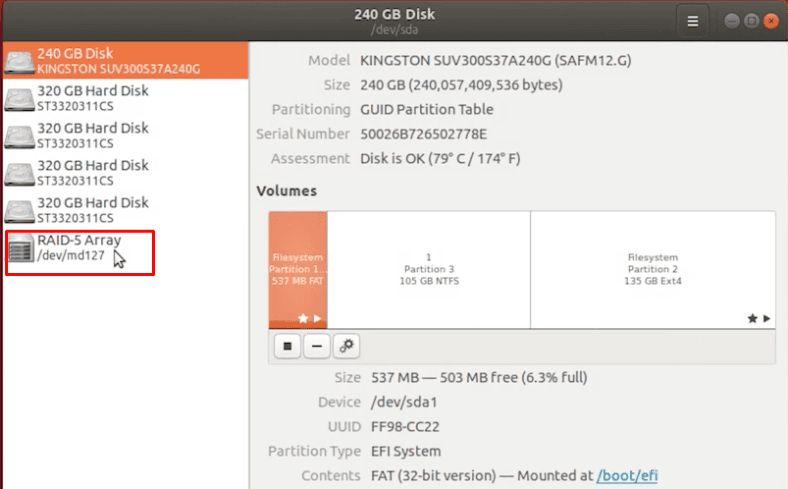
Тип RAID-5 – это избыточный массив накопителей с чередованием, без определенного диска четности. Главная особенность этого типа, в том что массив гарантировано будет работать даже при поломке одного диска. Но, при попытке смонтировать его в Linux ничего не вышло. Чтобы исправить ситуацию, необходимо подключить чистый «винчестер» на место сломанного, или пересобрать с помощью ПО.
Тестовый RAID 5 состоит из 5 физических дисков, один из них гарантированно сломан. Добавляем их в виртуальную машину с Windows, запускаем Hetman RAID Recovery, массив обнаружен и все настройки и свойства указаны верно.
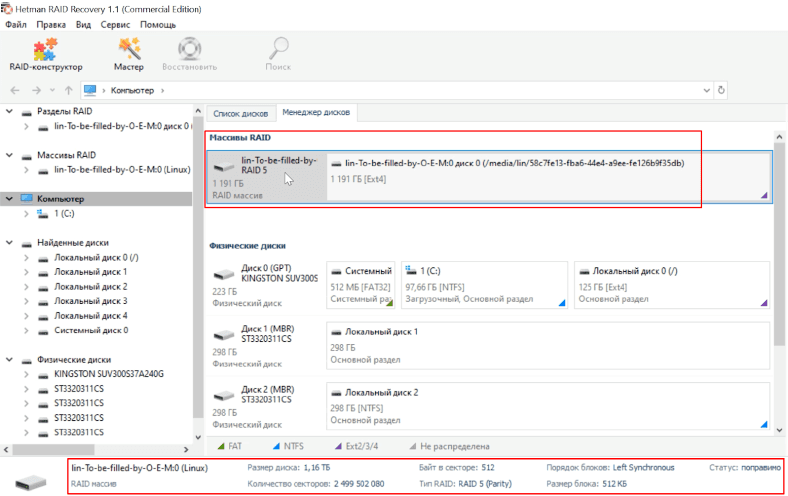
Как и положено один накопитель пустой. Так как это RAID 5, то снова запускаем быстрый анализ, находим нужные данные с помощью функции превью и восстанавливаем их. Когда процесс сохранения закончится, все файлы будут находится в выбранном каталоге.
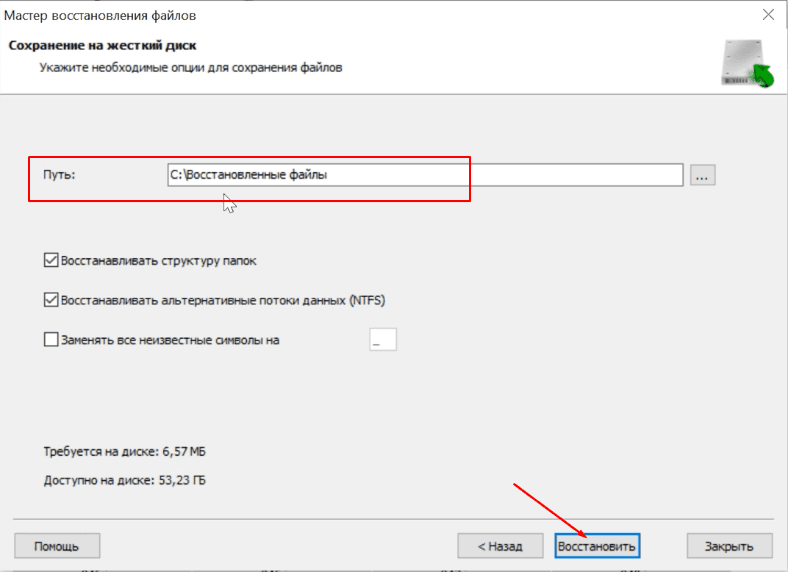
Теперь рассмотрим вариант когда повреждены два физических носителя из пяти. Программа обнаружила RAID, и два «винчестера» пустые.
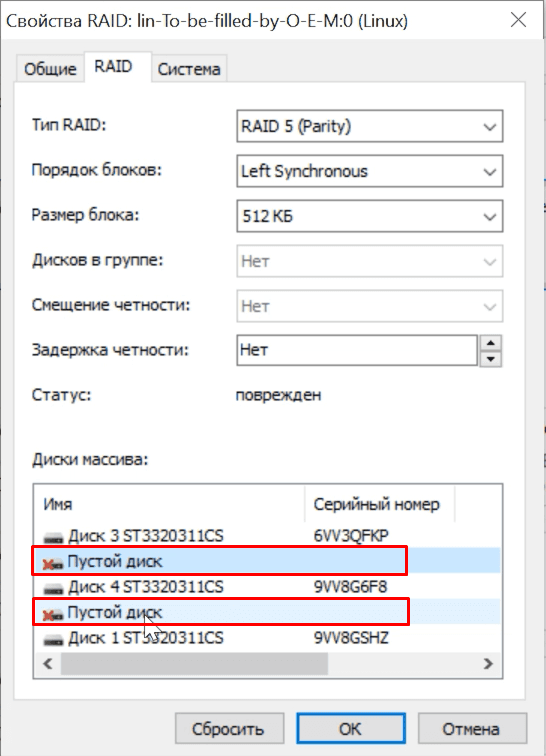
Восстановить данные с такого массива, задача непростая, запускаем полное сканирование, в зависимости от размеров «винчестеров» оно может длиться вплоть до суток. В итоге, программа нашла нетронутые данные, но несколько файлов частично или полностью стерты, их не получиться восстановить.
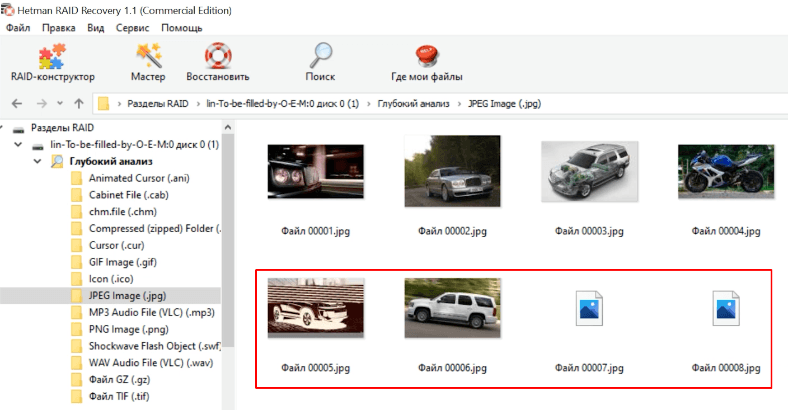
Если повреждены два или более физических носителя, RAID 5 становиться полностью неработоспособным, что сулит 100% потерю всех данных. Поэтому наш результат можно считать удовлетворительным.
Как восстановить данные RAID-0
Наш тестовый RAID 0 включает 5 жестких дисков, этот тип один из самых ненадежных. Фактически, это вообще не RAID, так как он не хранит избыточную информацию о хранящихся файлах. Если выйдет из строя хоть один «винчестер», то все устройство целиком нельзя монтировать в ОС. Все данные становятся недоступны.
Тип RAID-0 – это массив физических носителей с чередованием. Он показывает хорошую производительность благодаря высокой скорости чтения/записи, но отказ оборудования для него будет критическим. Посмотрим, сможем ли мы восстановить хоть часть потерянных данных.
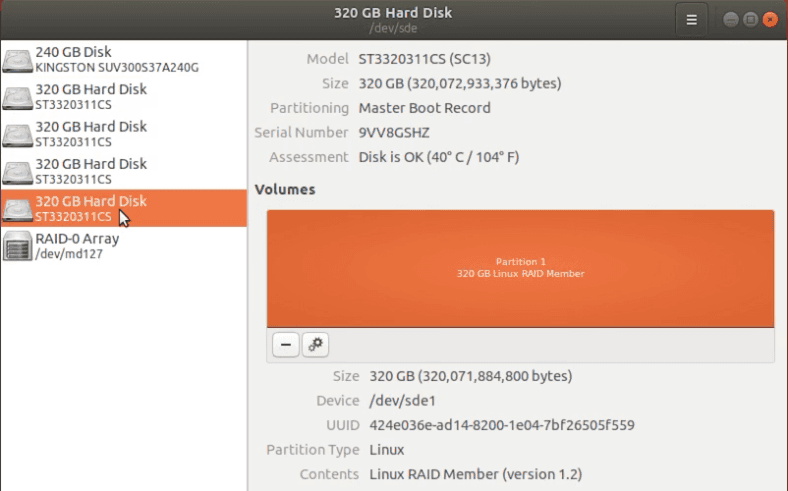
Добавляем диски в виртуальную машину и запускаем утилиту. Hetman Partition Recovery со скрежетом смогла правильно определить тип и свойства массива, один диск отображается пустым.
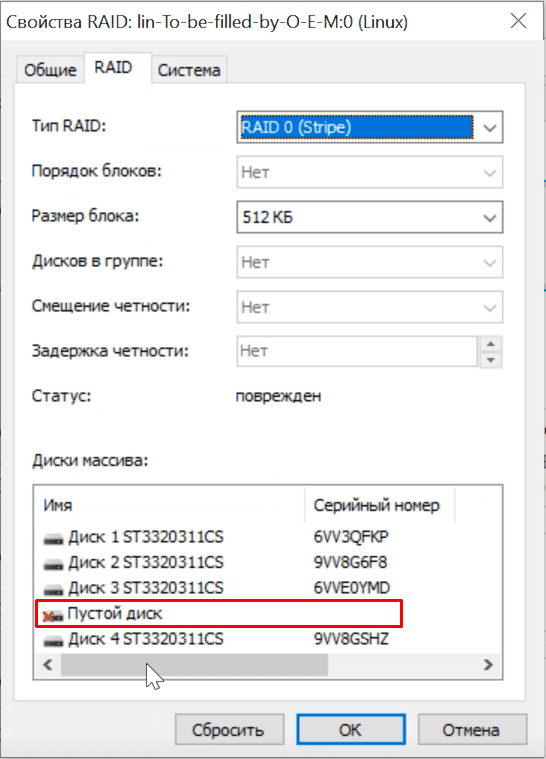
Быстрое сканирование бессмысленно, сразу запускаем глубокий анализ. Все живые файлы удалось обнаружить и просмотреть превью, но также много поврежденных данных. Выбираем файлы с помощью превью и кликаем «Восстановить».
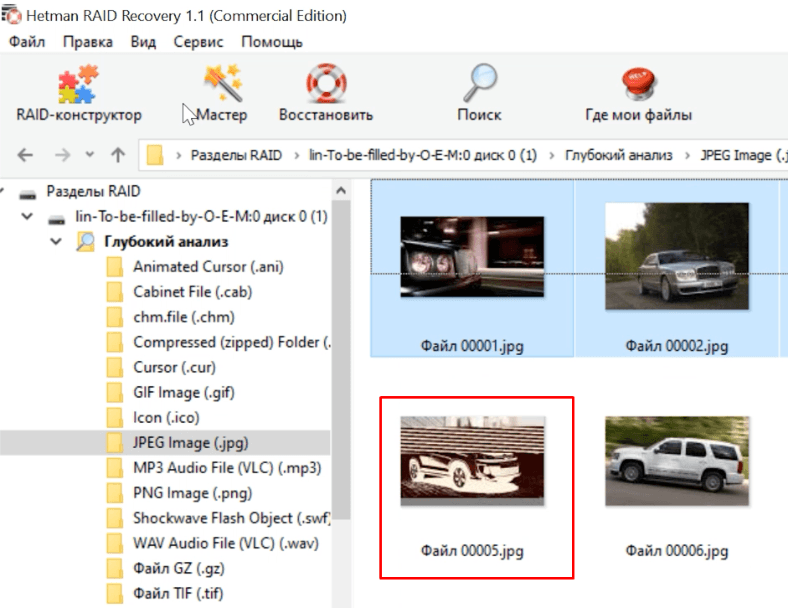
Вывод
Как показали тесты, количество восстанавливаемой информации напрямую зависит от типа массива. Данные с RAID 5 или 1 можно восстановить практически в полном объеме, благодаря «зеркалам» или избыточности информации. Даже при поломке нескольких жестких дисков, шансы вернуть большую часть нужных файлов достаточно высока.
Выход из строя хоть одного носителя, для RAID 0 становиться критическим. В большинстве случаев вы сможете восстановить только малую часть хранящихся данных. Что касается программы, то она смогла в автоматическом режиме распознать подключенные диски и правильно определить тип массива, что дало возможность уже восстанавливать файлы.
Полную версию статьи со всеми дополнительными видео уроками смотрите в источнике.
debian raid1 BOOT_DEGRADED. inird не хочет собирать массив, если отключить от машины один из дисков
Доброе утро всем!
Есть debian jessie minimal. Два диска в raid1, корень на /dev/md0. С двумя дисками все Ок. Как только отключаю один из дисков — initrd не хочет собирать /dev/md0. md0 появлятеся, но пишет статус inactive, Raid level : raid0 (вместо 1). Если в консоли восстановления сделать следующее:
Подскажите плиз, что надо прописать загрузчику и initramfs, чтобы при загрузке собирался degraded массив?
Заранее всем спасибо.
ps: Сори что повторно создал тему. Думаю, что тут более понятно все описал. Предыдущий топик: grub2 and sortware raid1 не грузится с одним диском.
pps: Вот как ставилась система
Cразу после установки стартую скрипт:
Версия ядра и разделы:

зачем вообще саму систему на рейд пихать, у меня на зеркалах только данные с которыми работает ОС расположены, а ценность самой ОС ноль целых хрен десятых.
- Показать ответы
- Ссылка
а в /boot/grub/grub.cfg как написано?
- Показать ответ
- Ссылка

md0 появлятеся, но пишет статус inactive, Raid level : raid0 (вместо 1).
Для того самого диска, с которым не грузится, покажи
- Показать ответ
- Ссылка
И покажи фотографию с /proc/mdstat, когда
md0 появлятеся, но пишет статус inactive, Raid level : raid0 (вместо 1)
- Показать ответ
- Ссылка
И покажи фотографию с /proc/mdstat, когда
вручную стартует нормально:
Для того самого диска, с которым не грузится, покажи madam -E.
это на запущеной системе с двумя подключенными дисками.
зачем вообще саму систему на рейд пихать
на сервере не только ценность данных важно, но и отказоустойчивость. Все сую в зеркало /boot / и даже swap
в этом примере — просто тест на виртуалке
- Показать ответы
- Ссылка
Создаю /etc/initramfs-tools/scripts/init-premount/assemble-md0 следующего содержимого:
chmod +x этому скрипту и update-initramfs -u — все ок. Но как то оно криво. Должен же быть метод заставить initrd собирать зеркало c одного диска простым указанием параметра типа bootdegraded=true md-mod.start_dirty_degraded=1 bootdelay=5000.
на сервере не только ценность данных важно, но и отказоустойчивость.
сам по себе сервер никакой отказоустойчивости не обеспечивает, этим занимаются кластеры HA, самый простенький можно построить на дрбд из двух нод, в нем падает один сервант, тут же поднимается второй и оба они используют один и тот же набор данных, зеркалирующихся по сети.
у вас же попытка повысить надежность дисковой подсистемы на которой размазана сама ОС, что для меня является сомнительным мероприятием.
- Показать ответы
- Ссылка
Так, давайте еще раз. Была дана ссылка на howtoforge с мануалом. Там сказано что надо set root='(md/0)’. И далее : The important part in our new menuentry stanza is the line set root='(md/0)’ — it makes sure that we boot from our RAID1 array /dev/md0 (which will hold the /boot partition) instead of /dev/sda or /dev/sdb which is important if one of our hard drives fails — the system will still be able to boot.
все сервисы суйте в виртуалки и размещайте их на кластерах, или держите их на san-ах, вот это и сохранность данных и отказоустойчивость.
- Показать ответ
- Ссылка
Ну так если умирает системный винт, который не в рейде, то это увеличивает время простоя сервера, ведь быстрее сунуть другой винт, который отзеркалился бы. Или не так?
- Показать ответы
- Ссылка

сам по себе сервер никакой отказоустойчивости не обеспечивает, этим занимаются кластеры HA, самый простенький можно построить на дрбд из двух нод, в нем падает один сервант блаблабла
ключевой момент здесь — «падает», чего можно легко избежать создав зеркало для системы, потому что переключение на другую ha ноду создаёт простой.
ведь быстрее сунуть другой винт, который отзеркалился бы. Или не так?
да все так, но помимо винтов на сервере есть чему ломаться, плюс зеркало не отменяет бекапов и повреждений самой ФС.
в кластере же (при смерти системного диска/дисков или еще какой беды на активной ноде) всю работу на себя возьмет другая нода, либо в случае хранилки san, виртаулки перезапустятся на других серверах(нодах), в это время спокойно делаем ремонт.
- Показать ответ
- Ссылка
Ну так если умирает системный винт
вово. А тут удлил дохлый из массива. отключил его (можно и на горячую). И воткнул новый. И даже ребутаться не надо. Правда на debian не пробовал. не знаю как там ядро себя поведет по поводу всяких там sata hotplug
Так, давайте еще раз. Была дана ссылка на howtoforge с мануалом. Там сказано что надо set root='(md/0)’
Статью читал. И прописывал так. Тут без разницы как root указывать. Можно и через uuid. Дело в том, что и grub и initrd и ядро все види нормально. Оно же грузится с двух дисков. И груб загружается с каждого в отдельности. и в grub shell> ls (md/0)/boot все видит. grub грузит ядро и initrd. он тут вообще не причем. Вся проблема в том, что initrd не хочем поднимать зеркало, если там отсутствует один из дисков.
бекапы вообще ничто не отменяет
Недавно сдох диск не с системой. Слава богу данные были на DRBD и в виртуалках. Кластер. Рейда не было. Бекап был, но не потребовался слава богу. В итоге траха на 4 часа. Миграция виртуалок — время простоя, пришлось ждать конца рабочего дня. После замены диска DRBD синхронизировалась 25 часов. а если бы был рейд — траха никакого, винт в рейде поменять — 5 минут. система и данные однозначно на рейде.
тут уже все вроде бы сказали про это. Нужно смоделировать отказ любой детальки системы и далее расписать какие сервисы отвалятся, что работать не будет, что нужно будет сделать и т.д. ВИНТЫ — это по моему самая частая деталь которая ломается — расходник.
а если бы у меня сломался системный диск который не в рейде да и еще в рабочее время? Короче труба. Внешнее хранилище позволить себе не могу.
Ну так есть у кого еще какие идеи по поводу BOOT_DEGRADED? Неужели в debian нельзя по дефолту (либо указанием какого-нить флага/параметра) загрузить систему с неполным raid1?
- Показать ответ
- Ссылка
10. Для предотвращения незагрузки машины, по причине того, что рейд находится в degraded состоянии добавляем bootdegraded=1 опцию ядра.
сам не пробовал, просто вспомнил — недавно читал после своего сбоя винта в кластере.
- Показать ответ
- Ссылка
а вот это не работает. Везде пишут, что это для ubuntu. Думал и в дебиане аналогично, но нет.
FreeBSD: Замена сбойного диска в zpool raid 1 или raid 10
FreeBSD: Замена сбойного диска в zpool raid 1 или raid 10
По сути операция идентична для обоих raid
До сбоя:
# zpool status -v
pool: zroot
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
zroot ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada0p2 ONLINE 0 0 0
ada1p2 ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
ada2p2 ONLINE 0 0 0
ada3p2 ONLINE 0 0 0
errors: No known data errors
Вырубаем один диск на горячую ada0p2:
# zpool status -v
pool: zroot
state: DEGRADED
status: One or more devices has been removed by the administrator.
Sufficient replicas exist for the pool to continue functioning in a
degraded state.
action: Online the device using ‘zpool online’ or replace the device with
‘zpool replace’.
scan: none requested
config:
NAME STATE READ WRITE CKSUM
zroot DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
6419677237496703848 REMOVED 0 0 0 was /dev/ada0p2
ada1p2 ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
ada2p2 ONLINE 0 0 0
ada3p2 ONLINE 0 0 0
errors: No known data errors
Перезагрузимся, ничего не поменяется, при выключении уже можно вставить новый диск
# shutdown -r now
# zpool status -v
pool: zroot
state: DEGRADED
status: One or more devices has been removed by the administrator.
Sufficient replicas exist for the pool to continue functioning in a
degraded state.
action: Online the device using ‘zpool online’ or replace the device with
‘zpool replace’.
scan: none requested
config:
NAME STATE READ WRITE CKSUM
zroot DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
6419677237496703848 REMOVED 0 0 0 was /dev/ada0p2
ada0p2 ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
ada1p2 ONLINE 0 0 0
ada2p2 ONLINE 0 0 0
errors: No known data errors
# ls -l /dev/ad*
crw-r—— 1 root operator 0x3f Dec 11 14:55 /dev/ada0
crw-r—— 1 root operator 0x41 Dec 11 14:55 /dev/ada0p1
crw-r—— 1 root operator 0x52 Dec 11 14:55 /dev/ada0p2
crw-r—— 1 root operator 0x40 Dec 11 14:55 /dev/ada1
crw-r—— 1 root operator 0x53 Dec 11 14:55 /dev/ada1p1
crw-r—— 1 root operator 0x54 Dec 11 14:55 /dev/ada1p2
crw-r—— 1 root operator 0x57 Dec 11 14:55 /dev/ada2
crw-r—— 1 root operator 0x5a Dec 11 14:55 /dev/ada2p1
crw-r—— 1 root operator 0x5b Dec 11 14:55 /dev/ada2p2
Вставили новый диск например на горячую без разметки, определился:
# ls -l /dev/ad*
crw-r—— 1 root operator 0x3f Dec 11 14:55 /dev/ada0
crw-r—— 1 root operator 0x41 Dec 11 14:55 /dev/ada0p1
crw-r—— 1 root operator 0x52 Dec 11 14:55 /dev/ada0p2
crw-r—— 1 root operator 0x40 Dec 11 14:55 /dev/ada1
crw-r—— 1 root operator 0x53 Dec 11 14:55 /dev/ada1p1
crw-r—— 1 root operator 0x54 Dec 11 14:55 /dev/ada1p2
crw-r—— 1 root operator 0x57 Dec 11 14:55 /dev/ada2
crw-r—— 1 root operator 0x5a Dec 11 14:55 /dev/ada2p1
crw-r—— 1 root operator 0x5b Dec 11 14:55 /dev/ada2p2
crw-r—— 1 root operator 0x63 Dec 11 15:17 /dev/ada3
Уберем старый диск в оффлайн:
# zpool offline zroot 6419677237496703848
# zpool status -v
pool: zroot
state: DEGRADED
status: One or more devices has been taken offline by the administrator.
Sufficient replicas exist for the pool to continue functioning in a
degraded state.
action: Online the device using ‘zpool online’ or replace the device with
‘zpool replace’.
scan: none requested
config:
NAME STATE READ WRITE CKSUM
zroot DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
6419677237496703848 OFFLINE 0 0 0 was /dev/ada0p2
ada0p2 ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
ada1p2 ONLINE 0 0 0
ada2p2 ONLINE 0 0 0
errors: No known data errors
Сделаем разметку и загрузочную метку:
# gpart backup ada2 > /tmp/ada2.backup
# gpart restore ada3 => 40 10485680 ada3 GPT (5.0G)
40 1024 1 freebsd-boot (512K)
1064 984 — free — (492K)
2048 10481664 2 freebsd-zfs (5.0G)
10483712 2008 — free — (1.0M)
# gpart bootcode -b /boot/pmbr -p /boot/gptzfsboot -i 1 ada3
partcode written to ada3p1
bootcode written to ada3
Указываем на замену диска:
# zpool replace zroot 6419677237496703848 /dev/ada3p2
Make sure to wait until resilver is done before rebooting.
If you boot from pool ‘zroot’, you may need to update
boot code on newly attached disk ‘/dev/ada3p2’.
Assuming you use GPT partitioning and ‘da0’ is your new boot disk
you may use the following command:
gpart bootcode -b /boot/pmbr -p /boot/gptzfsboot -i 1 da0
Все ок:
# zpool status -v
pool: zroot
state: ONLINE
scan: resilvered 287M in 0 days 00:00:04 with 0 errors on Wed Dec 11 15:22:07 2019
config:
NAME STATE READ WRITE CKSUM
zroot ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ada3p2 ONLINE 0 0 0
ada0p2 ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
ada1p2 ONLINE 0 0 0
ada2p2 ONLINE 0 0 0